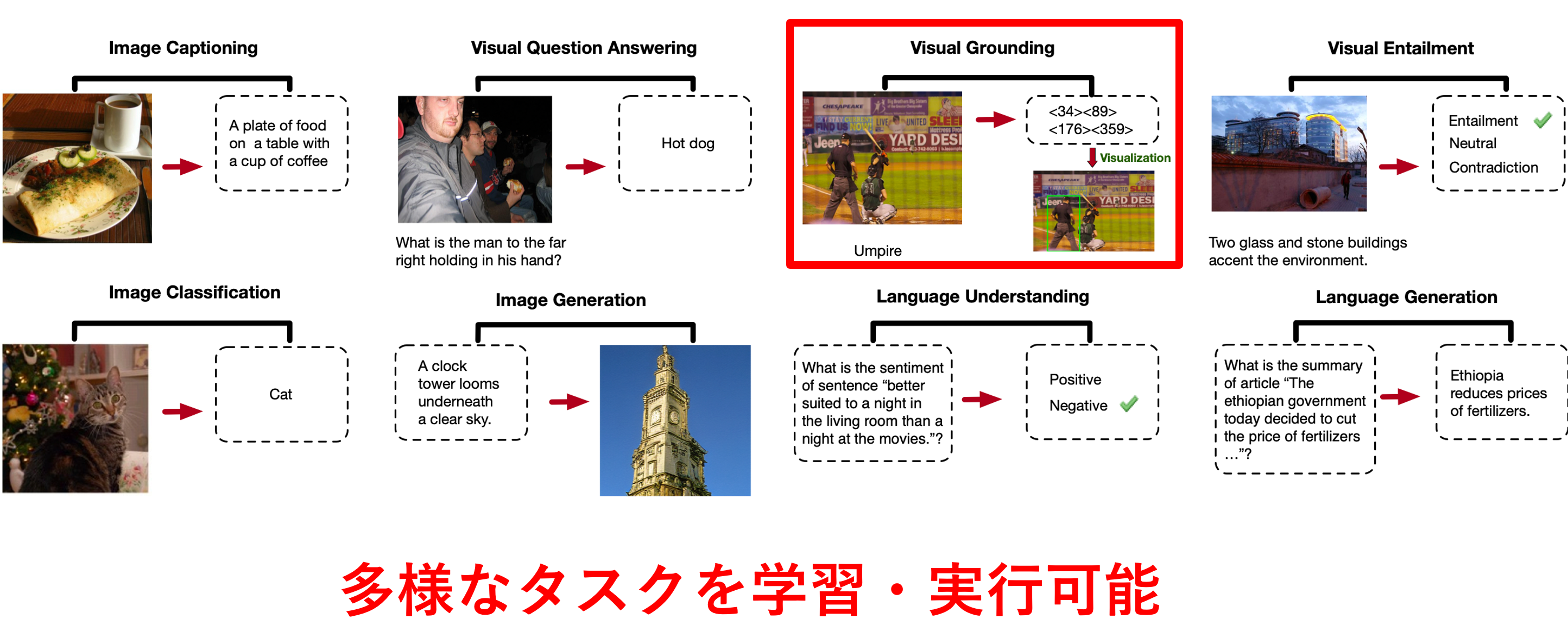
��現在の修士課程での研究内容は「視覚言語モデル(VLM)を物体検出を伴う特定の下流タスクにより効果的に適応させるファインチューニング手法の考案」です。画像と言語を両方扱い多様なタスクを実行できる視覚言語モデル(VLM)は大量のデータで複数のタスクを同時に事前学習しており、下記のようなImage Captioning(画像キャプション生成)・Visual Question Answering(画像に関する質問応答)・Image Classification(画像クラス分類)といった多様なタスクを実行できます。その中には画像中の物体を矩形で囲ってモデルに出力させるVisual Groundingのような物体検出タスクも含まれます。
- 上:視覚言語モデル「OFA」が実行可能な視覚言語タスク一覧
こうした多様なタスクを実行可能なVLMの活用用途として、特定の下流タスクでより高い性能が出せるようにファインチューニング(微調整)して利用することが考えられます。その中には物体検出を伴う下流タスクも存在します。物体検出を伴う下流タスクというのは例えばVisual Groundingや下記のようなGrounded Image Captioning(画像中の物体を含むキャプションを生成し、物体に対応した領域も出力するタスク)が考えられます。
しかし、こうした下流タスクへモデルを微調整するために必要な学習データセットの作成には、クラス・テキストに対応した画像中の物体がどこにあるかを表す物体領域�をバウンディングボックス(bbox)やセグメンテーションマスクのアノテーションが必要になります。しかし基本的に物体領域のアノテーションコストは高いため、できるだけ少量のデータで下流タスクに適応できるのが望ましいです。
- Grounted Image Captioningの例(Kosmos-2)

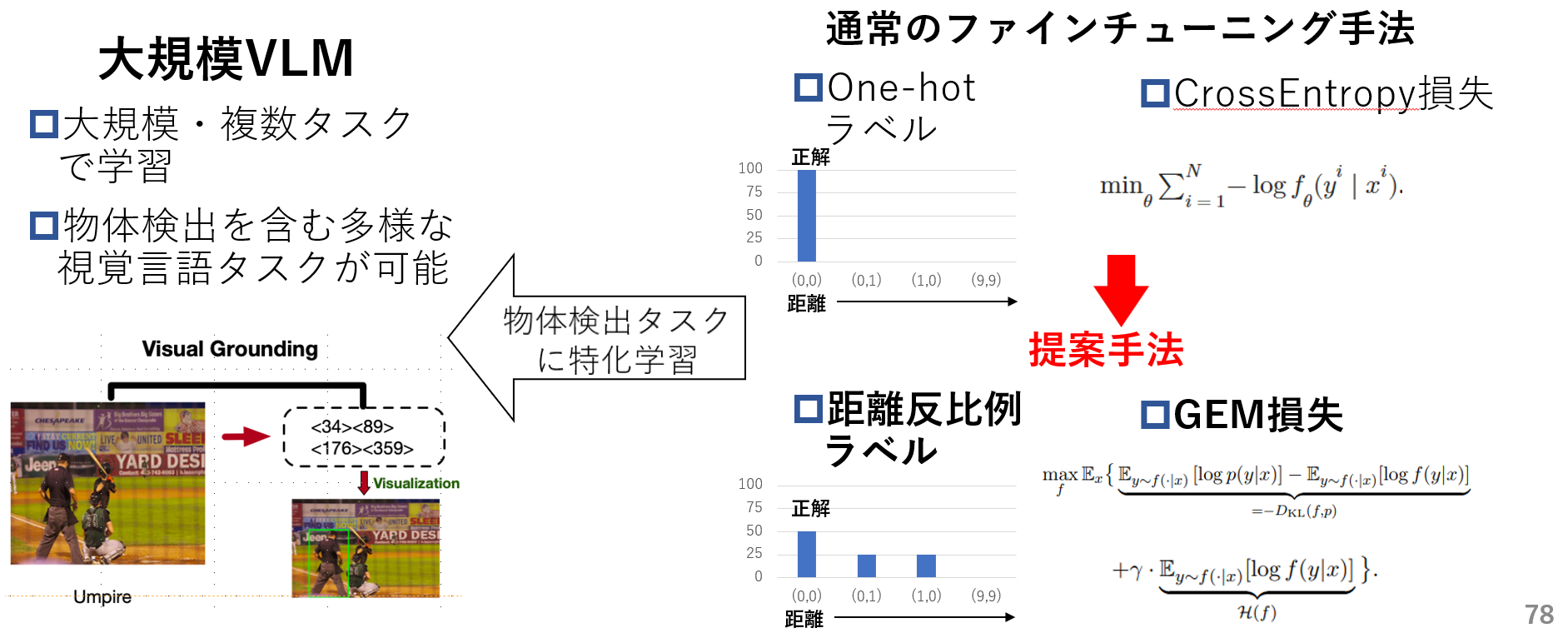
そのため本研究ではVLMを物体検出を伴う下流タスクに適応させる際、1.距離反比例ラベルと2.GEM損失関数(既存手法)を用いて通常のOne-hotラベルとCrossEntorpy(CE)損失関数を用いた場合より、より効果的な微調整手法を提案します。
- 提案手法概要