卒業研究ではKosmos-2という既存のマルチモーダルモデル(MLLM)を使用してChain of thoughtと物体領域によるマルチモーダルモデルによる説明性の実現を目指しました。
マルチモーダルモデルを含むAIモデルにはなぜそのような出力をしたのかわからないブラックボックス性の問題があります。しかし、最近自然言語処理分野でLLMに質問を入力した際、出力となる解答に加え解答に対する根拠となる思考過程を出力するChain of Thought(思考連鎖、CoT)という研究が登場しました。またCoTがモデルの出力に対する説明になることに着目し、CoTをマルチモーダルモデルに適用したという研究も登場しました。私はこの先行研究を発展させ着目し物体領域を扱えるマルチモーダルモデルでの説明性の実現を卒業研究で目指しました。
具体的には質問に対してテキストによる言語的説明だけでなく、物体領域による視覚的説明の両方を行えるモデルを構築しました。例えば下記の画像の左のようにAIモデルが画像に関する質問に答える際、言葉だけではどの人物を指しているかわかりません。 しかし、右のようにテキストに対応した領域をモデルが出力することで容易に人物を認識できるようになります。

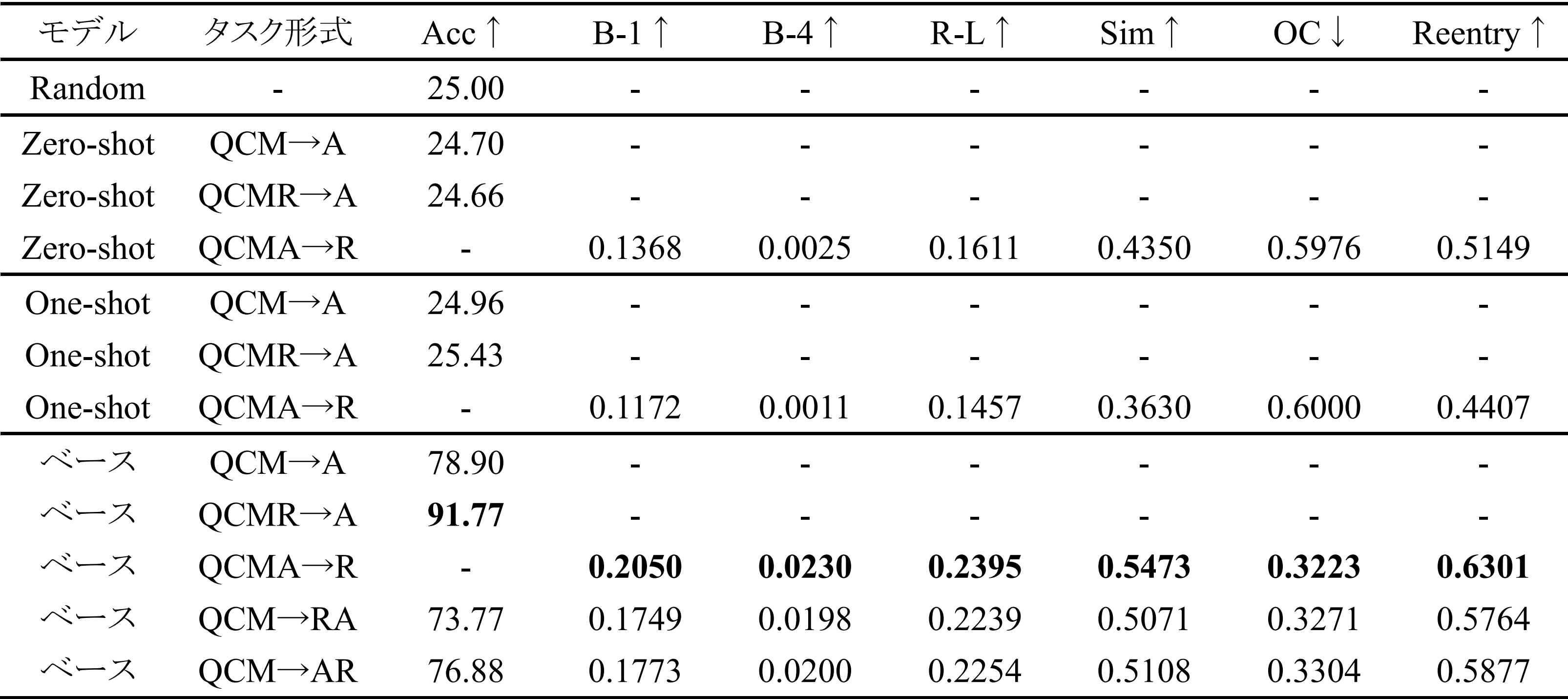
下記画像のようにマルチモーダルモデルのKosmos-2に画像と質問文と解答選択肢と画像内の物体の領域を入力し、根拠テキストとそれに含まれる物体の領域と解答を出力させることで研究のアイデアを実現しました。データセットはVisual Commonsense Reasoningという既存の領域付多選択式質問応答データセットを利用しました。

モデルは根拠テキストと物体領域と選択した解答を出力するためそれぞれ評価しました。出力した根拠テキストはテキストの評価指標であるBLUE、ROUGE、SentenceBert Similarity Scoreで行いました。物体領域の評価はOC-costで行いました。解答は記号が一致するかのAccuracyで評価しました。
実験は学習なしのKosmos-2のZero-shot(解答例なし)とOne-shot(解答例1つ)、VCRデータセットで学習したKosmos-2で比較実験を行いました。結果VCRデータセットで学習したKosmos-2(ベース)が最も高い性能となりました。
- 図はTest分割での実験結果。表中の↑は値が大きいほど評価が高いことを表し、↓は値が小さいほど評価が高いことを表す。また、“-”はそのタスク形式においてその評価指標で評価していないことを表す。
実際のKosmos-2の出力例を以下に載せます。
-
正解している例:男性がハープに触れていないことをモデルが見れている。

-
間違っている例:モデルが犬を見れておらず間違った根拠を生成している。

今後はより高性能なモデルで実験をしてより高精度の解答ができるようにしたいと思います。