現在の研究内容は「複数画像でのIn-Context Learning(ICL)が可能なマルチモーダルモデルの構築」です。LLMやマルチモーダルモデルは大規模なため、追加学習には非常に高いコストがかかります。ICLはモデルに人間がタスクの具体例(入力と出力の例)を見せるこ�とで、モデルの能力を向上し未知タスクも解けるようになる手法です。下記画像は画像質問応答でのICLの例です。
- 上:Kosmos-1でのICLなしのZero-shotの例、下:1つの具体例によるICL(One-shot)の例
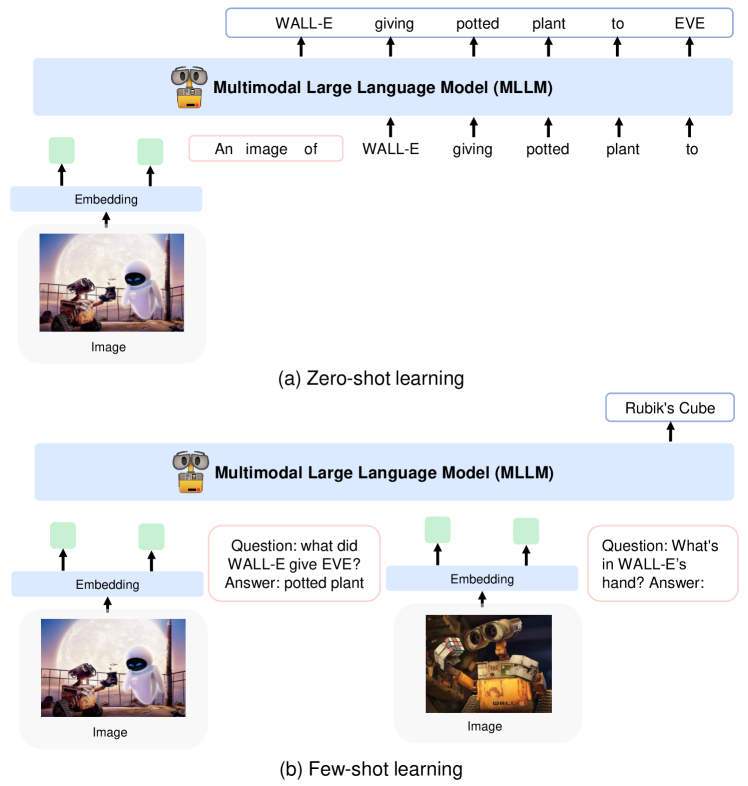
ICLではモデルの重みを更新する追加学習を行う必要がないため、低いコストで目的のタスクにモデルを適用できます。そして、複数画像でのICL可能なマルチモーダルモデルを構築することで、テキストだけでなく画像でも人間が具体例を与えられるようになります。このモデルの実用化例としては、ICLにより良品と不良品の画像・説明文の例をモデルに見せるだけで未知製品に対する外観検査や官能検査を低コストで行えるようになることが考えられます。